Introduction to Text-to-Music Retrieval#
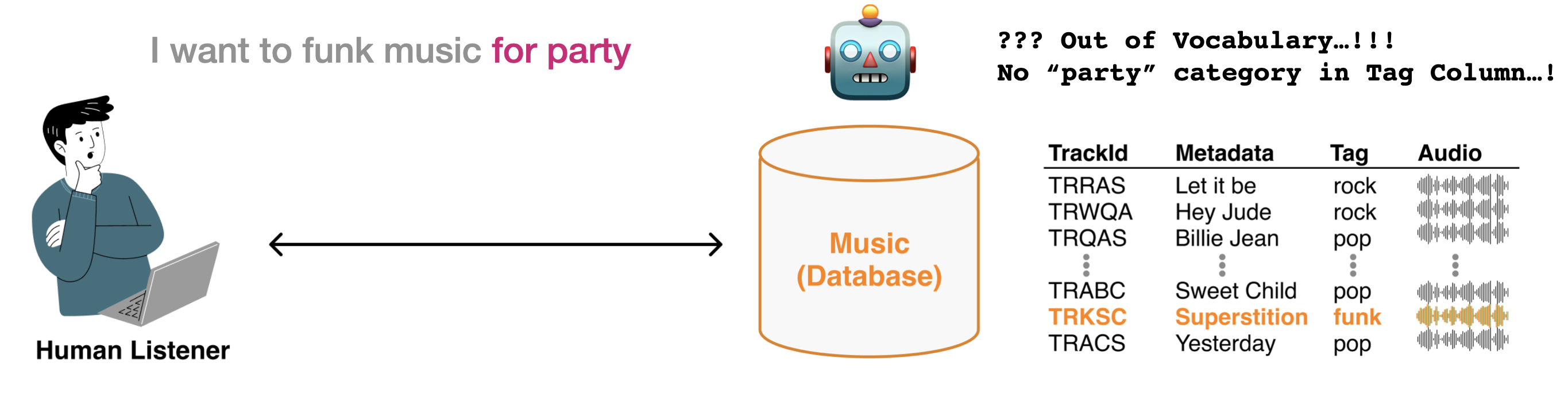
Music retrieval is the task of finding a set of music pieces that match a given query. Early Text-to-Music Retrieval has been studied for a long time under the names “query-by-text” [TBTL08] or “query-by-description” []. As previously explained, the initial systems were built using Supervised Classification.
Note
“query-by-text” system can retrieve appropriate songs for a large number of musically relevant words. … we describe such a system and show that it can both annotate novel audio content with semantically meaningful words and retrieve relevant audio tracks from a database of unannotated tracks given a text-based query. We view the related tasks of semantic annotation and retrieval of audio as one supervised multiclass, multilabel learning problem. [TBTL08]
However, the vocabulary of the datasets we use unfortunately only contains between 50 and 200 words, and when a user wants to search for music using words outside of this vocabulary, an Out of Vocabulary problem occurs. As a result, we face the need to search for desired music even in open vocabulary problem. If we try to solve this using supervised classification, we would need an enormous number of classification models for each task, and it would be too costly to convert all user queries into data. In this chapter, we introduce joint embedding-based retrieval models used to reflect various user text queries, and also introduce conversational music search models that can not only find music but also generate responses.