Overview of Tutorial#
This tutorial will present the changes in music understanding, retrieval, and generation technologies following the development of language models.
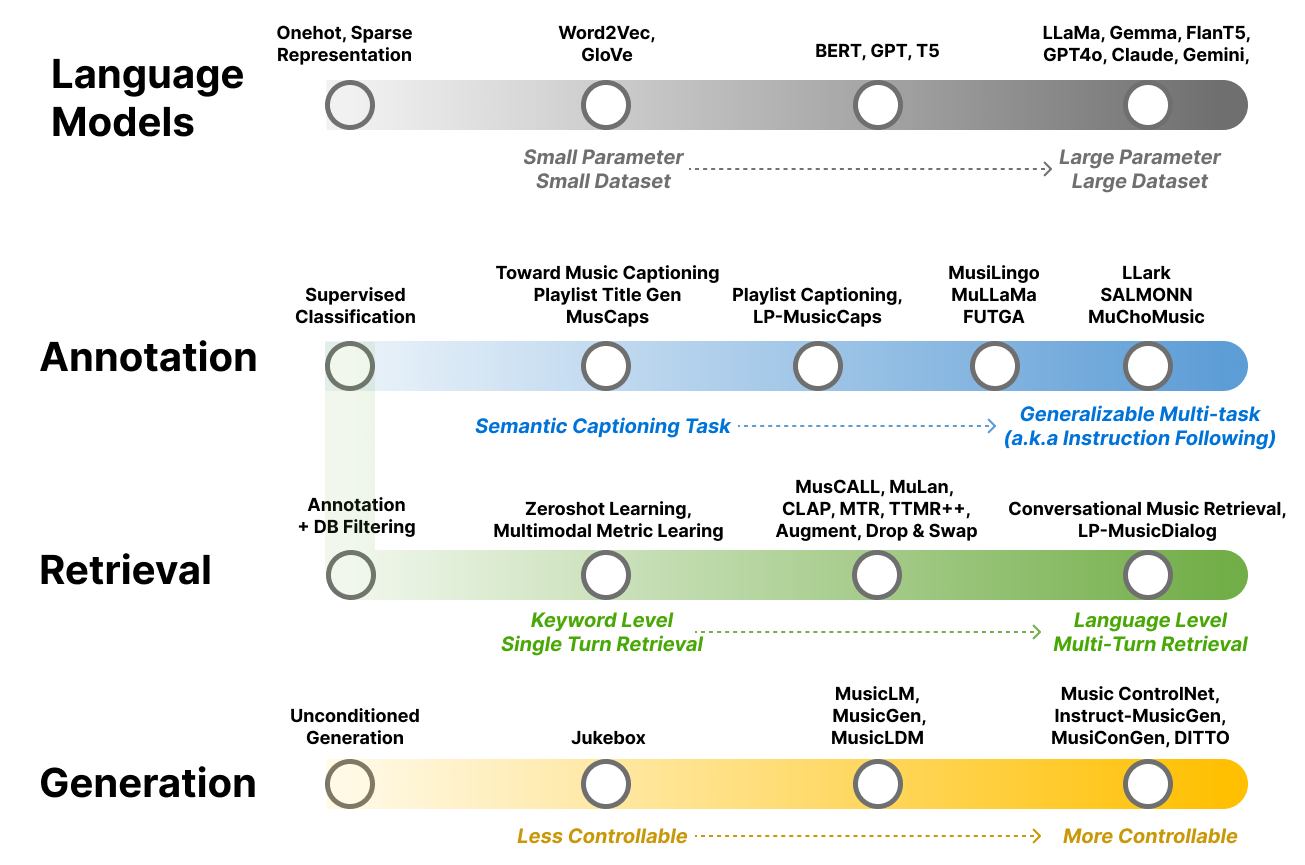
Fig. 3 Illustration of the development of music and language models.#
Langauge Models#
Chapter 2 presents an introduction to language models (LMs), essential for enabling machines to understand natural language and their wide-ranging applications. It traces the development from simple one-hot encoding and word embeddings to more advanced language models, including masked langauge model [DCLT18], auto-regressive langauge model [RWC+19], and encoder-decoder langauge model [RSR+20], progressing to cutting-edge instruction-following [WBZ+21] [OWJ+22] [CHL+24] and large language models [AAA+23]. Additionally, the chapter demonstrates how language models are utilized in various domains, such as vision and speech, highlighted by examples such as joint embedding techniques like CLIP [RKH+21], encoder-decoder frameworks like Whisper [RKX+23], and text-driven image generation models like DALL-E [RPG+21].
Music Annotation (Music -> Natural Language)#
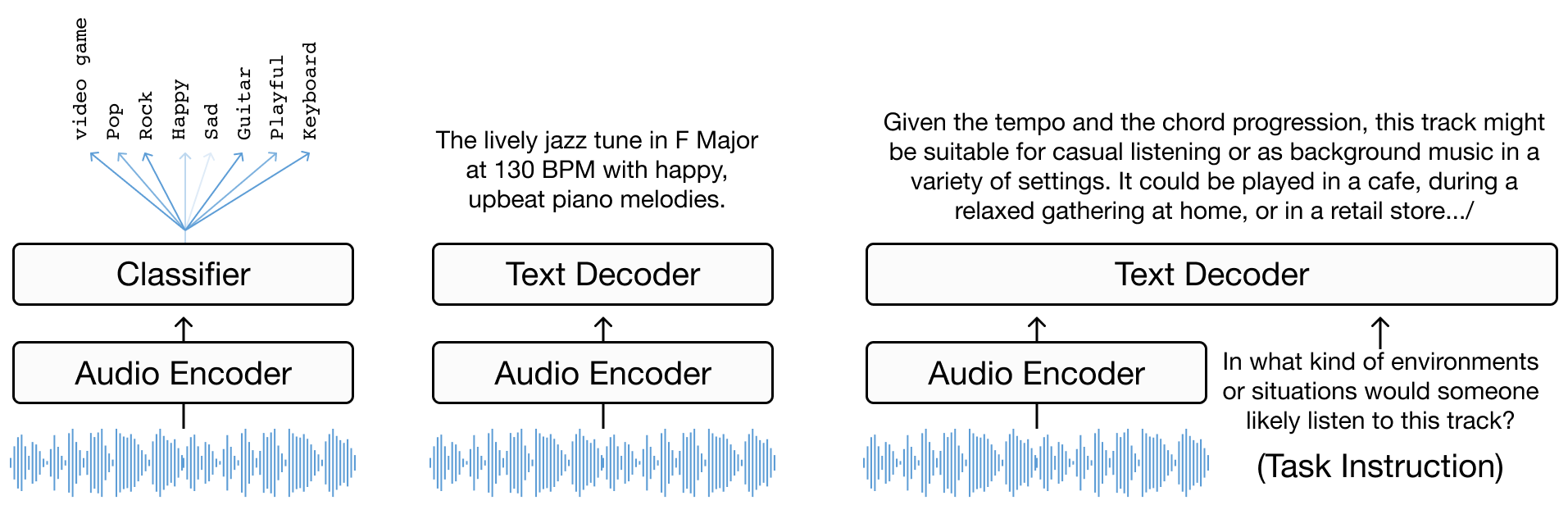
Chapter 3 offers an in-depth look at music annotation as a tool for enhancing music understanding. It begins with defining the task and problem formulation, transitioning from basic classification [TBTL08] [NCL+18] to more complex language decoding tasks. The chapter further explores encoder-decoder models [MBQF21] [DCLN23] and the role of multimodal large language models (LLMs) in music understanding [GDSB23]. The chapter explores the evolution from task-specific classification models to more generalized multitask models trained with diverse natural language supervision.
Music Retrieval (Natural Language -> Database Music)#
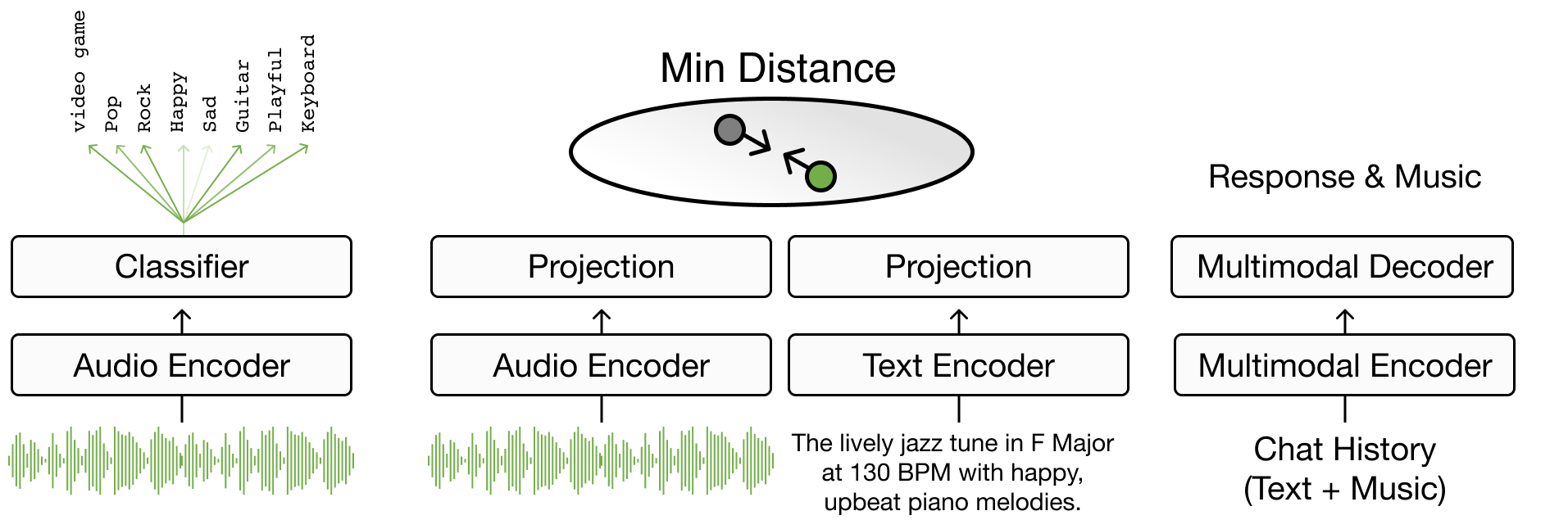
Chapter 4 focuses on text-to-music retrieval, a key component in music search, detailing the task’s definition and various search methodologies. It spans from basic boolean and vector searches to advanced techniques that bridge words to music through joint embedding methods [CLPN19], addressing challenges like out-of-vocabulary terms. The chapter progresses to sentence-to-music retrieval [HJL+22] [MBQF22a] [DWCN23], exploring how to integrate complex musical semantics, and conversational music retrieval for multi-turn dialog-based music retrieval [CLZ+23]. It introduces evaluation metrics and includes practical coding exercises for developing a basic joint embedding model for music search. This chapter focuses on how models address users' musical queries in various ways.
Music Generation (Natural Language -> Sampled Music)#
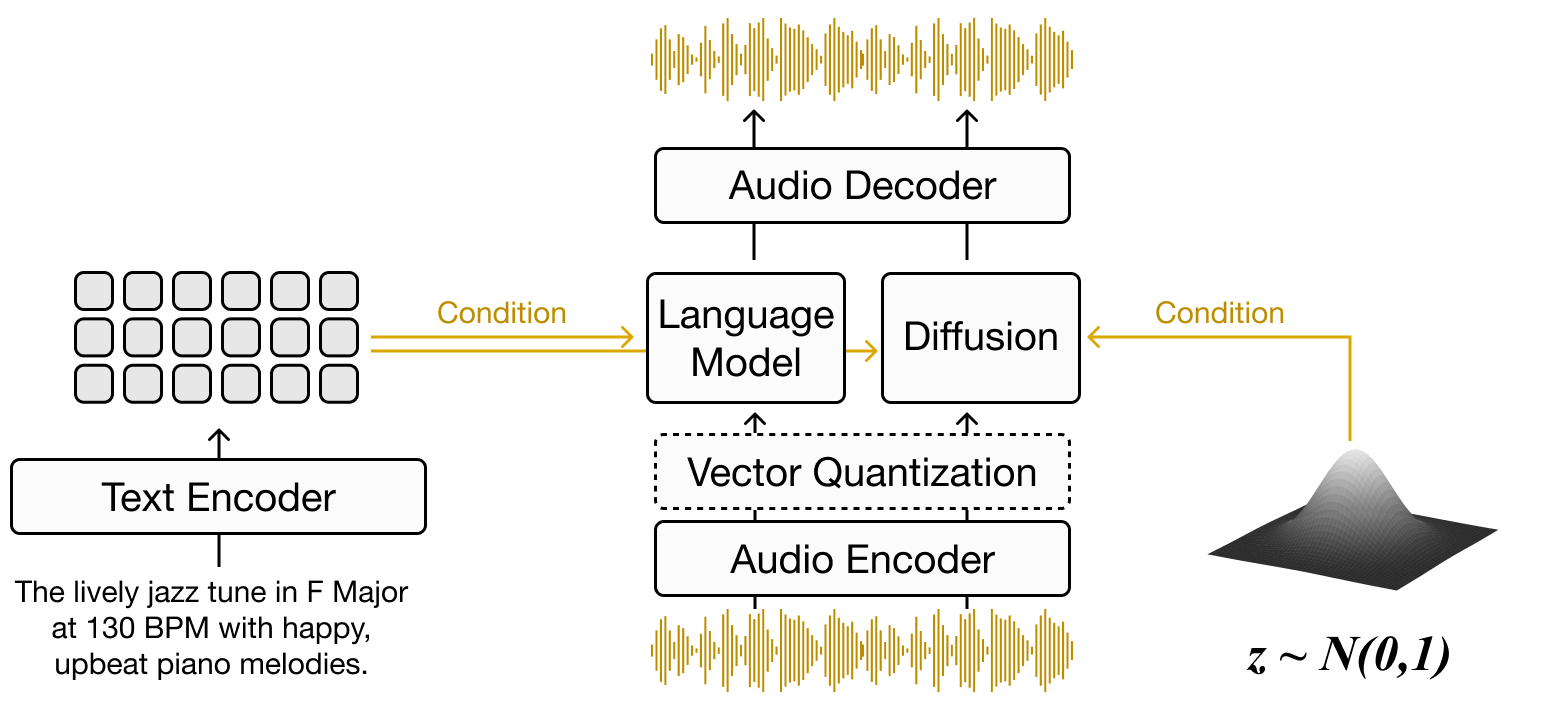
Chapter 5 delves into the creation of new music through text-to-music generation techniques, emphasizing the production of novel sounds influenced by text prompts [DJP+20]. It introduces the concept of generating music without specific conditions and details the incorporation of text-based cues during the training phase. The discussion includes an overview of pertinent datasets and the evaluation of music based on auditory quality and relevance to the text. The chapter compares music generation methods, including diffusion models [CWL+23] and discrete codec language models [ADB+23] [CKG+24]. Furthermore, it examines the challenges associated with purely text-driven generation and investigates alternative methods of conditional generation that go beyond text, such as converting textual descriptions into musical attributes [WDWB23] [NMBKB24].